





Introduction to Reinforcement Learning
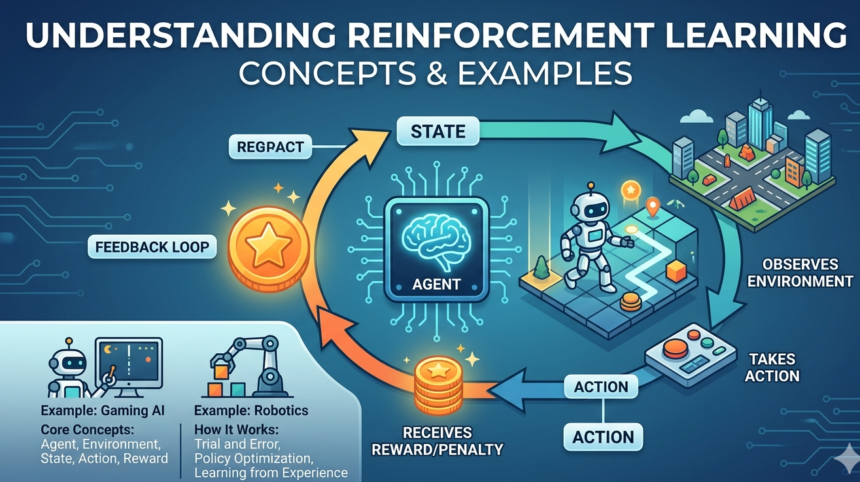
Reinforcement Learning (RL) is a pivotal area within the broader field of machine learning, distinct in its approach to achieving optimal outcomes. Unlike supervised learning, which relies on labeled data to train models, RL focuses on an agent that learns to make decisions through trial and error. The agent interacts with an environment and receives feedback in the form of rewards or penalties based on its actions, fostering a learning process that mirrors natural learning behaviors.
The significance of reinforcement learning in artificial intelligence cannot be overstated. RL algorithms are fundamentally designed to solve complex decision-making problems, enabling systems to perform tasks that require adaptive behavior. For instance, RL has been effectively employed in various domains such as robotics, gaming, and autonomous vehicles, demonstrating its versatility and power in real-world applications. By learning from interactions, the agent can improve its strategies over time, optimizing its performance.
The foundational principles of reinforcement learning are structured around the concepts of states, actions, and rewards. The environment is defined in terms of its states, capturing the various scenarios in which an agent may find itself. The agent then selects actions to either explore new possibilities or exploit known strategies, all while striving to maximize cumulative rewards over time. The learning process is guided by a reward function, which evaluates the desirability of outcomes achieved through each action, thus driving the agent’s learning trajectory.
Ultimately, reinforcement learning holds the potential to revolutionize how machines learn and adapt, setting the stage for advancements in artificial intelligence that can handle increasingly complex tasks. By understanding its core principles and mechanisms, researchers and developers can leverage RL to create intelligent systems that autonomously improve their performance across a wide array of applications.



Key Terminology in Reinforcement Learning
Reinforcement learning, a pivotal facet of artificial intelligence, employs a unique set of terminologies that are essential for understanding its framework. At the core of this learning paradigm is the agent, which is the entity that interacts with the environment to make decisions. The agent learns from its experiences and progressively refines its behavior through a process of trial and error.
The environment refers to the context or system in which the agent operates. It encompasses everything that the agent interacts with, including external conditions and factors that impact the agent’s decision-making process. Understanding the agent-environment interaction is crucial, as it illuminates how behaviors are shaped in response to environmental stimuli.
Critical to the learning process are rewards, which are feedback signals received by the agent as a consequence of its actions. Rewards can be positive, encouraging the agent to repeat specific actions, or negative, discouraging certain behaviors. This feedback mechanism drives the agent towards achieving its goals by maximizing cumulative rewards over time.
The state of the environment encapsulates all relevant information at a specific time, defining the conditions under which the agent makes decisions. The agent observes the current state and utilizes it to determine the best course of action. Complementing the concept of state is the notion of actions, which are the choices made by the agent based on the current state. Each action results in a transition to a new state, potentially impacting future rewards and decisions.
Grasping these key terms—agent, environment, rewards, states, and actions—is fundamental for anyone looking to delve deeper into reinforcement learning and its applications. Understanding these concepts paves the way for more advanced discussions and practical implementations in the realm of AI.
The Reinforcement Learning Process
Reinforcement learning (RL) is a unique branch of machine learning where an agent learns to make decisions through continuous interaction with its environment. This process is characterized by a cycle of trial and error, where the agent’s learning is driven by feedback from the environment based on its actions. The agent receives a state from the environment, selects an action, and subsequently receives a reward signal, which plays a crucial role in guiding its decision-making process.
The core of reinforcement learning revolves around the concept of exploration versus exploitation. Exploration involves the agent trying new actions to discover their effects on the environment, while exploitation refers to the agent using its existing knowledge to maximize its rewards. Striking a balance between these two strategies is vital; too much exploitation can lead to suboptimal performance if the agent overestimates the benefits of previously learned policies, whereas excessive exploration may hinder the agent’s ability to capitalize on its gained knowledge.
Over time, through this iterative process, the agent develops a policy—a mapping from states to actions—which defines its behavior in the given environment. The objective of the agent is to optimize this policy to maximize its cumulative reward over time. The effectiveness of the RL process hinges on the agent’s ability to refine its policy based on past experiences, ultimately leading to improved decision-making capabilities as it learns from its success and failures.
This learning framework is implemented in various applications, ranging from robotics and gaming to recommendation systems. By understanding the reinforcement learning process, researchers and practitioners can leverage it to develop intelligent systems capable of adapting to their surroundings and driving complex decision-making tasks.
Types of Reinforcement Learning Algorithms
Reinforcement learning encompasses a variety of algorithms, each designed to tackle unique challenges in the learning process. Prominent among these are Q-learning, Deep Q-Networks (DQN), Policy Gradients, and Actor-Critic methods.
Q-learning is a model-free reinforcement learning algorithm that relies on a value function to inform an agent’s decision-making. It allows agents to learn optimal policies by utilizing a Q-table to store the value of each action in a given state. The primary advantage of Q-learning is its simplicity and effectiveness in smaller state spaces. However, its performance diminishes in larger environments, making it less effective in complex scenarios.
Deep Q-Networks (DQN) build on the foundational principles of Q-learning by integrating deep learning techniques. In DQN, a neural network is used to approximate the Q-function, allowing it to handle high-dimensional input spaces such as images. This algorithm exhibits improved performance in complex environments; however, it also introduces challenges like instability and the requirement of extensive computational resources for training.
Policy Gradient methods represent a different approach, focusing directly on optimizing the policy rather than estimating the value function. By updating the policy weights based on the gradient of expected rewards, these methods can handle large action spaces effectively. Policy Gradients are particularly useful in continuous action environments, although they often converge more slowly compared to value-based methods.
Lastly, Actor-Critic methods combine both value-based and policy-based approaches by utilizing two separate networks: one for the policy (the actor) and one for the value function (the critic). This hybrid strategy facilitates a balanced improvement, learning both long-term and immediate rewards simultaneously. Nevertheless, the implementation complexity can be a drawback, requiring careful tuning of parameters to achieve optimal performance.
Real-World Applications of Reinforcement Learning
Reinforcement learning (RL) is increasingly being utilized across various sectors, demonstrating its robustness and versatility in solving complex decision-making problems. One prominent application of RL is in robotics. Robots can learn to perform tasks such as grasping objects or navigating environments through trial and error, driven by feedback from their actions. For instance, reinforcement learning algorithms enable robots to optimize their movements over time, improving efficiency and accuracy in real-world tasks. This has significant implications for industries where automation is essential.
Another noteworthy application is in game AI, particularly exemplified by systems like AlphaGo, developed by DeepMind. AlphaGo employs deep reinforcement learning to play the ancient game of Go, surpassing human expertise. Through self-play and reinforcement from its successes and failures, the AI learned to make strategic decisions, highlighting the potential of RL in developing advanced cognitive functionalities. This success in gaming translates into lessons for real-life strategy optimization and resource allocation.
In the financial sector, reinforcement learning is leveraged for algorithmic trading. Traders can use RL models to make real-time buy or sell decisions based on market conditions. By maximizing their rewards—which could be profits over time—these models learn to navigate complex financial data. This results not only in improved trading strategies but also in the ability to adapt to changing market dynamics more effectively.
Moreover, healthcare is transforming with reinforcement learning. It is used in personalized medicine, where treatment plans can be tailored based on individual responses. For example, RL algorithms can analyze how patients respond to various treatments and learn the optimal care pathways over time. This personalization paves the way for improved patient outcomes and resource utilization in healthcare delivery.
Challenges in Reinforcement Learning
Reinforcement learning (RL) stands as an innovative approach to machine learning but is not without its challenges. One of the primary challenges encountered is the problem of sparse rewards. In many practical applications, the agent may take numerous actions without receiving any feedback, making it difficult to determine which actions yield beneficial outcomes. This sparsity can lead to inefficient learning, as the agent may spend significant time exploring actions that provide little to no reward signal.
Another significant obstacle is the requirement for extensive amounts of training data. Reinforcement learning algorithms often need substantial interactions with the environment to converge to an effective policy. This extensive data requirement can be particularly taxing in real-world applications, where gathering data might involve time-consuming or expensive processes. Consequently, the need for large datasets can limit the applicability of RL in domains where such data is not readily obtainable.
Moreover, generalization across different environments poses another challenge in reinforcement learning. An RL model trained in one environment may perform poorly when applied to another, potentially leading to overfitting on the specific context in which it was trained. Updating models for varied environments is an ongoing area of research, where the goal is to create architectures that can extract transferable knowledge across different situations.
Research efforts are actively being directed towards tackling these challenges. Techniques such as reward shaping aim to provide more frequent feedback to the learning agent, while advancements in simulation-based training are seeking to reduce the dependency on real-world data. Additionally, meta-learning approaches are being explored to enhance the generalization capabilities of reinforcement learning agents, making them more versatile across variable environments.
Future Trends in Reinforcement Learning
The field of reinforcement learning (RL) is rapidly evolving, driven by recent advancements in artificial intelligence (AI) research, the development of new algorithms, and enhancements in computational hardware. As we look to the future, several trends are poised to shape the landscape of reinforcement learning and expand its applications across various sectors.
First and foremost, we can expect a significant increase in the integration of RL with other machine learning paradigms, such as supervised and unsupervised learning. This hybrid approach could facilitate the development of more sophisticated models capable of tackling complex tasks that require both decision-making and pattern recognition. Additionally, the ongoing research into multi-agent systems, where multiple RL agents interact within an environment, is likely to lead to more advanced simulations and real-world applications, particularly in areas like robotics and autonomous systems.
Emerging technologies such as quantum computing also hold promise for enhancing the efficiency of reinforcement learning algorithms. Quantum computing’s ability to perform computations at unprecedented speeds may allow for faster training times and more complex problem-solving capabilities. As these technologies mature, we may witness breakthroughs in RL that were previously unattainable.
Furthermore, the application of reinforcement learning in diverse fields is set to expand significantly. Industries such as healthcare, finance, and logistics are increasingly exploring RL for optimization problems and decision-making processes. For example, RL can be utilized to optimize treatment plans in healthcare or to improve supply chain logistics in e-commerce settings.
As hardware continues to advance, particularly with the advent of specialized processors for machine learning, we can anticipate more efficient implementations of RL algorithms. This advancement will not only enhance the performance of existing systems but could also lead to the emergence of new applications that leverage the strengths of reinforcement learning in innovative ways.
Comparisons with Other Learning Paradigms
Reinforcement learning is one of the key paradigms in machine learning, distinct from supervised and unsupervised learning approaches. Understanding these differences is crucial for practitioners aiming to select the most appropriate algorithm for their tasks.
In supervised learning, models are trained using labeled data, where input-output pairs are clearly defined. This approach is advantageous for tasks with well-defined objectives, such as image classification or sentiment analysis. However, the dependence on labeled datasets can be a limitation, especially in scenarios where acquiring labels is difficult or costly. When the environment is static and the relationship between inputs and outputs is clear, supervised learning excels in providing precise predictions.
Conversely, unsupervised learning operates without labeled outputs, focusing instead on discovering patterns or structures within the input data. Examples of unsupervised learning include clustering and dimensionality reduction techniques, which can help in exploratory data analysis. The merit of unsupervised learning lies in its flexibility and ability to handle vast amounts of data. However, its major drawback is the difficulty involved in evaluating model performance, given the absence of explicit feedback.
Reinforcement learning stands apart by emphasizing an agent’s interaction with an environment to maximize cumulative rewards. It thrives in dynamic settings where the optimal actions are not predefined but must be learned through trial and error. Although reinforcement learning demonstrates remarkable success in areas like robotics, gaming, and recommendation systems, it also faces significant challenges, such as the need for substantial computation and the potential for inefficient learning pathways due to exploration-exploitation trade-offs.
Overall, while reinforcement learning offers unique advantages in certain contexts, careful consideration is essential when contrasting it with supervised and unsupervised learning paradigms. Depending on the specific requirements and characteristics of the problem at hand, selecting the most suitable learning approach can significantly influence the outcomes of machine learning endeavors.
Conclusion
Reinforcement learning (RL) stands out as a powerful paradigm within the broader domain of artificial intelligence (AI), showcasing the ability of agents to learn optimal behaviors through interactions with their environments. Key takeaways from our exploration include an understanding of core concepts such as agents, environments, rewards, and policies, which together form the foundation of RL systems. Unlike traditional supervised learning methods, which rely on labeled datasets, reinforcement learning emphasizes the role of trial and error, where agents receive feedback from their actions. This mechanism allows RL systems to adapt and improve over time, making them particularly valuable in fields requiring decision-making under uncertainty.
Throughout the discussion, we highlighted several applications of reinforcement learning that underscore its significance in contemporary AI. From training autonomous vehicles to optimizing supply chains and enhancing game playing capabilities, RL has proven instrumental in solving complex, dynamic challenges. Its ability to model real-world scenarios and learn from them equips it with unique advantages, setting the stage for further innovations.
As we conclude, it is essential for readers to consider the implications of reinforcement learning on future technologies. Its continual evolution presents numerous opportunities for research and development, prompting enthusiasts to engage with cutting-edge advancements. Exploring resources such as academic papers, online courses, and community forums can deepen understanding and foster collaboration in this exciting field. For those intrigued by the potential of AI, delving deeper into reinforcement learning offers a pathway to contributing to the next wave of technological breakthroughs. Embrace the journey of discovery within the fascinating realm of reinforcement learning.









